Ch12. Recognition
포스트 : 2022.12.20.
최근 수정 : 2022.12.20.
What Matters in Recognition?
Learning Techniques
- E.g. choice of classifier or inference method
Representation
- Low level: SIFT, HoG, gist, edges
- Mid level: Bag of words, sliding window, deformable model
- High level: Contextual information
Data
- More is always better
- Annotation is the difficult part
Video Google System
- Collect all words within query region
- Inverted file index to find relevant frames
- Compare word counts
- Spatial verification
Simple idea
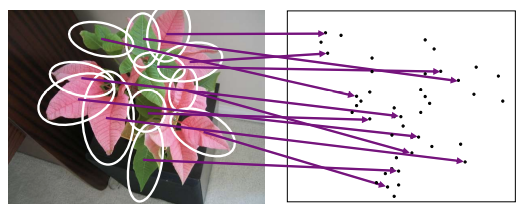
See how many keypoints are close to keypoints in each other image
⇒ slow
Indexing local features
When we see close points in feature space, we have similar descriptors, which indicates similar local content.
Visual words
Map high-dimensional descriptors to tokens/words by quantizing the feature space
- Quantize via clustering, let cluster centers be the prototype words
- Determine which word to assign to each new image region by finding the closest cluster center

Issues:
- Vocabulary size, number of words
- Sampling strategy : grid or interest points
- Clustering / quantization algorithm
- Unsupervised vs. supervised
- What corpus provides features (universal vocabulary?)
Inverted file index

Instance recognition
remaining issues
-
How to summarize the content of an entire image? And gauge overall similarity?
Bags of visual words
- Summarize entire image based on its distribution (histogram) of word occurrences.
- Comparing bags of words : nearest neighbor search
- Inverted file index and bags of words similarity
- Extract words in query
- Inverted File index to find relevant frames
- Compare word counts
-
How large should the vocabulary be? How to perform quantization efficiently?
Recognition with K-tree
Use Maximally Stable Extremal Regions by Matas et al. and then extract SIFT descriptors from the MSER regions.
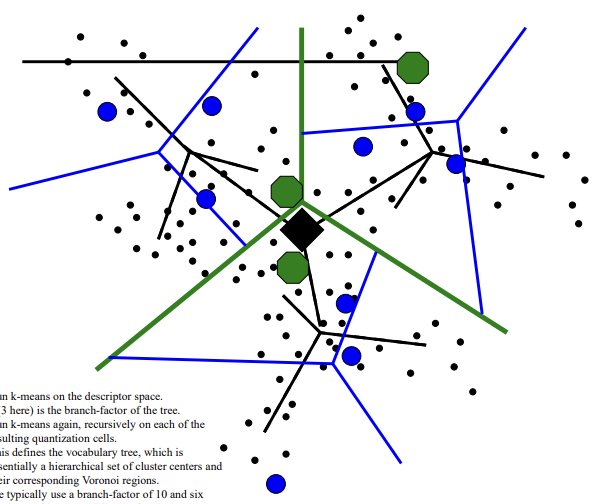
- Run k(branch-factor of the tree / 3 here)-means on the descriptor space
- Run k-means again, recursively on each of the resulting quantization cells.
- This defines the vocabulary tree, which is essentially a hierarchical set of cluster centers and their corresponding Voronoi regions.
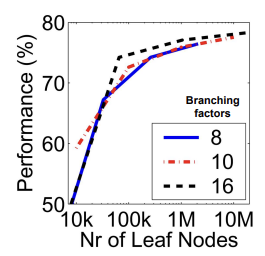
- We typically use a branch-factor of 10 and six levels, resulting in a million leaf nodes
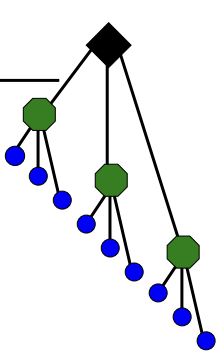
- In order to add an image to the database, we perform feature extraction. Each descriptor vector is now dropped down from the root of the tree and quantized very efficiently into a path down the tree, encoded by a single integer.
- Each node in the vocabulary tree has an associated inverted file index.
- Number of words given tree parameters
- branching factor
- number of levels
- Higher branch factor works better (but slower)
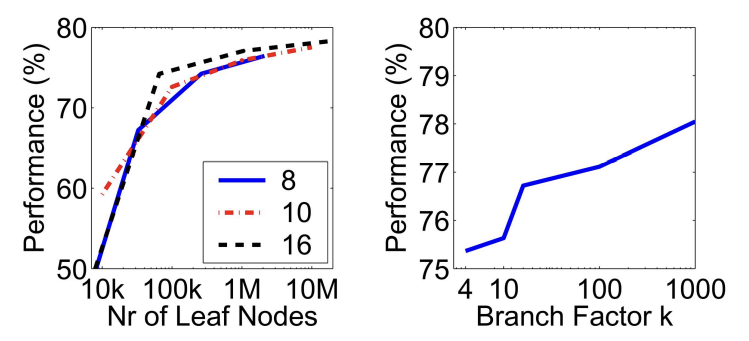
- Word assignment cost vs. flat vocabulary
- sampling strategies
- sparse, at interest points
- dense, uniformly
- randomly
- multiple interest operators
-
Is having the same set of visual words enough to identify the object/scene? How to verify spatial agreement?
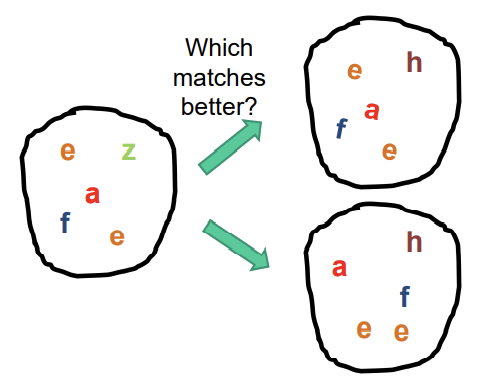
- with spatial information, first one is better
- without, there is no difference
Spatial Verification


-
How to score the retrieval results?
💡
tf-idf weighting
Tern frequency - inverse document frequency
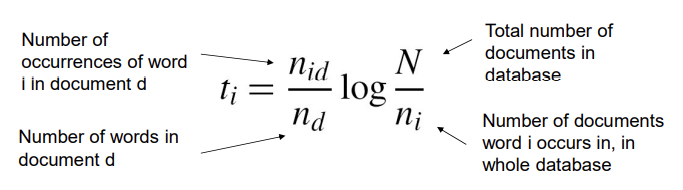
Query Expansion
query → results → spatial verification → new query → new results
Keys to efficiency
Simple approach : Keypoint matching
- All-pairs local feature matching is slow ⇒ quantize features and build bag of feature representation. ⇒ Lossy ⇒ spatial verification can help
- Finding the overlap in visual words based on the Bags of Features is still too slow ⇒ interted file index, one lookup per word
- Even quantizing the local features into a visual word is too slow ⇒ vocabulary tree. ⇒ Lossy